Entry
Claude Opus 4.5 Unlocks the "No Restart" Workflow
Practical tips from two weeks of shipping with the best agentic model yet.
Filed6 min readvia substack
00 / Masthead
Entry
Practical tips from two weeks of shipping with the best agentic model yet.
Practical tips from two weeks of shipping with the best agentic model yet.
I have been using Claude Opus 4.5 for about two weeks now, and I need to share what I have found. Not the benchmarks. I will post those soon. But the thing that actually matters when you are trying to ship.
Here is the insight that hit me on Friday: I have not had to restart a single task.
If you have spent any time with agentic coding tools, you know the feeling. You write your spec, you hit go, and the model just... wanders off. Goes in a completely wrong direction. You sigh, kill it, rewrite your prompt, and try again. That restart tax adds up. It is not captured in any benchmark.
With Opus 4.5, that has not happened. Every task I have thrown at it has stayed on track. The model infers what I want, asks the right clarifying questions in plan mode, and executes. I have not had to throw work away.
That is the real unlock here.
It is getting genuinely hard to measure the difference between frontier models now. Opus 4.5, GPT 5.1, Gemini 3 Pro. The scores are close. I have my own evals, and the numbers cluster together in ways that make comparison feel almost arbitrary.
But benchmarks only tell you half the picture. They measure capability. They do not measure consistency, context inference, or the ability to stay aligned with your intent over a long task. Opus 4.5 wins on the stuff that does not show up in a leaderboard.
Martin Alderson makes a similar point: we might be in a GPT-4 style leap that evals simply cannot see. The real gains are in "taste," stability over long sessions, and reduced human intervention-none of which standard benchmarks measure.
McKay Wrigley’s deep dive on Opus 4.5 captures this well. He calls it the “unlock for agents” and compares it to a Waymo: you tell it where to go, and it takes you there. After a few of these experiences, your brain realises you live in this world now.
The pricing helps too. Opus 4.5 is dramatically cheaper than previous Opus models. The speed is there. For the average user doing serious work, the $100 Claude Pro subscription should be enough. I only hit the limits when I was running two or three projects simultaneously.
I do not write formal PRDs for every task. Opus 4.5 is extremely good at inferring what you want, especially if your project is already set up well.
If you have good ADRs, solid documentation in the repo, and a clear structure, Opus 4.5 will find its way around. It builds context from what is already there. When you use plan mode, it asks the right questions to fill in the gaps. You do not need to spoon-feed it.
My approach is half-spec: I write enough to establish intent and constraints, then let the model figure out the implementation details. It works because Opus 4.5 actually reads your codebase. It does not just pattern-match on your prompt. It understands the project
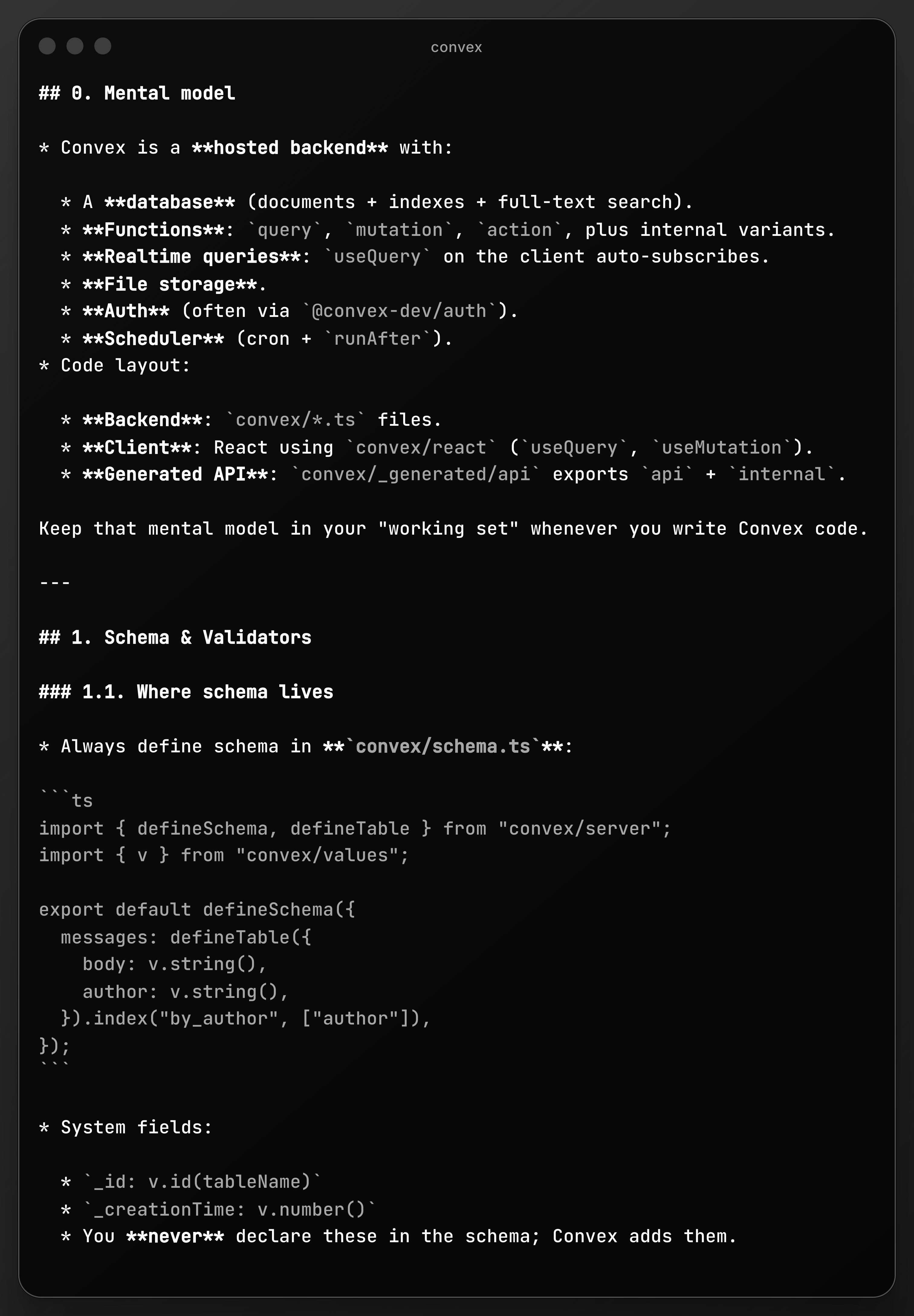 excerpt from my convex skill
excerpt from my convex skill
I do not like overloading Claude Code with plugins. Most of them add noise. But there are a few that have earned their place:
Frontend Design Skill - This is a must-have. The default output from AI coding tools still trends toward generic slop. This skill fixes that. To install:
/plugin marketplace add anthropics/claude-code /plugin install frontend-design@claude-code-plugins
Compound Engineering Plugin - Your mileage may vary here. The default plan mode in Claude Code is already good. But if you want more structured planning for complex features, give it a try.
Beads - I use this for task management within Claude Code. Simple and effective.
Custom Skills - I wrote my own skill for Convex-specific patterns. I extracted the common practices from Convex’s Chef project, turned them into a document, and used Claude Code to generate the skill. The key is progressive discovery: you do not dump everything into CLAUDE.md upfront. You let the agent discover context as it needs it.
Ultracite Hooks - I run Ultracite for linting on every file write. TypeScript projects get linted and type-checked automatically. This is the verification layer that lets me trust the output. Write good tests, write good evals, set up hooks, and you can let the agent work with high confidence.
Use them. Write your plan, then spawn agents to do the work in parallel. This is where the speed comes from.
I also still use other models for review. GPT 5.1 high or GPT 5.1 Pro as a reviewer via Repo Prompt sometimes catches different security issues or edge cases. You could probably skip this. I just like the extra layer. It is how I prefer to work.
Everyone is trying to build agents with pre-built platforms and workflow builders. Stop.
The Claude Agent SDK, the harness that powers Claude Code, is the most powerful agentic framework available right now. It is criminally underrated.
If you need to deploy agents for operations like service desk automation, SRE triage, or internal tooling, the Claude Agent SDK is by far the easiest way to build them right now. It is the same harness that powers Claude Code, with automatic context management, MCP extensibility, and built-in permissions. You can also run Claude Code in headless mode with -p for scripted tasks, or use the SDK directly in TypeScript or Python to build full production agents.
Yes, wrapping a web application around it takes effort. Deploying to cloud environments is not trivial. You need sandboxed, long-running compute, not serverless. But once you clear that hurdle, you have something far more capable than any drag-and-drop agent builder.
McKay called it “the best open secret in AI right now.” He is right.
I will be writing more about these kinds of agents soon.
I have been rebuilding DocIQ, my LegalTech application. It is a complex system: Convex backend, TanStack Start frontend, separate Python service for document manipulation. Data rooms, detailed permissions, security implications everywhere.
Opus 4.5 is racing through it. I shipped 45 features in a week. On the side. This is not my day job. Martin Alderson argues the cost of software may have just dropped 90%-that tracks with what I am seeing.
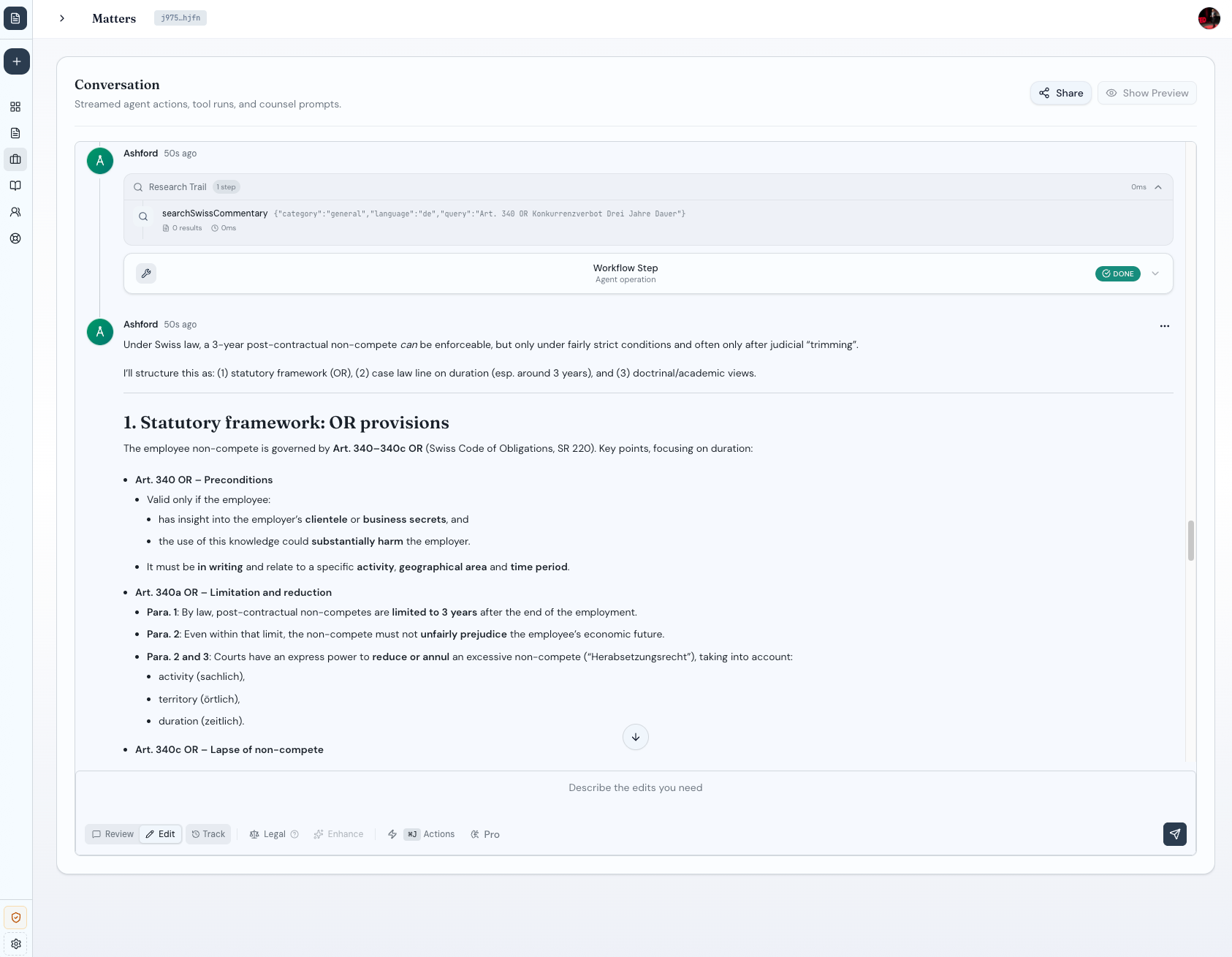
The code quality has been consistently high. But here is the number that matters: when I switched DocIQ’s internal agent from GPT 5.1 to Opus 4.5, the eval scores on end-to-end legal tasks jumped from 78% to 94%.
That is not a benchmark. That is my own eval suite, testing real agentic operations: legal searches, document manipulation, compliance checks. Opus 4.5 is meaningfully better at the complex, multi-step work that agents actually do.
(Shout out to Evalite for being such a solid eval library.)
I am rolling out this stack to one of our portfolio companies tomorrow. First real deployment with Opus 4.5 in a production environment. I am targeting a 2-3x improvement in delivery speed. I will share the KPIs when I have them.
Stay tuned. More numbers coming soon.